
Az új M1 Mac-ek élménye beköszöntött a való életbe.
Gyorsak. Nagyon gyorsak. De miért? Mi a varázslat?
Erik Engheim, 2020. november 28.
23 perces olvasmány

A YouTube-on megnéztem egy Mac-felhasználót, aki tavaly vett egy iMacet. 40 GB RAM-mal maximálták, ami körülbelül 4000 dollárba került. Hitetlenkedve nézte, hogyan bontja le túldrága iMacjét az új M1 Mac Mini, amelyért csekély 700 dollárt fizetett.
A valós életben végzett tesztek során az M1 Mac-ek nem pusztán elhaladnak a csúcskategóriás Intel Mac-ek mellett, hanem megsemmisítik azokat. Az emberek hitetlenkedve kezdték kérdezgetni, hogy a csudában lehetséges ez?
Ha te is azok közé tartozol, akkor jó helyen jársz. Azt tervezem, hogy emészthető darabokra bontjuk, pontosan mit csinált az Apple az M1-gyel. Konkrétan a következő kérdések merülnek fel szerintem sok emberben:
1. Mi a technikai oka annak, hogy az M1 chip olyan gyors?
2. Az Apple hozott néhány igazán egzotikus technikai döntést, hogy ezt lehetővé tegye?
3. Mennyire lesz könnyű az olyan versenytársaknak, mint az Intel és az AMD, hogy ugyanazokat a technikai trükköket megvalósítsák?
Természetesen megpróbálhatja ezt a Google-lal keresni, de ha megpróbálja megtudni, hogy az Apple mit csinált a felületes magyarázatokon túl, akkor gyorsan eltemetődik a rendkívül technikai szakzsargonban, mint például az M1, amely nagyon széles utasítások dekódereit, hatalmas újrarendezési puffert (ROB) stb. használ. Hacsak nem egy CPU-hardveres geek, ezek nagy része egyszerűen zabálás lesz. De ha igen, akkor nagyon ajánlom Andrei Frumusanu cikkét az AnandTech-nél, amely mélyen belenyúl a részletekbe. Az ő kemény munkájának és kutatásának köszönhető, hogy sok fontos műszaki részletet tudunk az M1-ről.
Hogy a legtöbbet hozhassa ki ebből a történetből, azt javaslom, hogy olvassa el korábbi írásomat: „Mit jelent a RISC és a CISC 2020-ban?” Itt elmagyarázom, mi az a mikroprocesszor (CPU), valamint számos fontos fogalmat, például:
- Utasításkészlet architektúra (ISA)
- Csővezetékezés (Pipeline)
- Betöltés/tárolás architektúra
- Mikrokód kontra mikroműveletek
De ha türelmetlen vagy, elkészítek egy gyors verziót az anyagból, amelyet meg kell értened, hogy értsd az M1 chipre vonatkozó magyarázatomat.
Mi az a mikroprocesszor (CPU)?
Általában, amikor Intel és AMD chipekről beszélünk, akkor központi processzorokról (CPU-k) vagy mikroprocesszorokról beszélünk. Amint arról többet olvashat a RISC kontra CISC írásomban, ezek az utasításokat a memóriából olvassák be. Ezután az egyes utasításokat jellemzően egymás után hajtják végre.
A CPU a legalapvetőbb szinten egy olyan eszköz, amely számos elnevezett memóriacellát, úgynevezett regisztert és számos számítási egységet, úgynevezett aritmetikai logikai egységeket (ALU) tartalmaz. Az ALU-k olyan dolgokat hajtanak végre, mint az összeadás, kivonás és egyéb alapvető matematikai műveletek. Azonban csak a CPU regiszterekben levő értékekkel dolgoznak. Ha két számot szeretne összeadni, akkor azt a két számot a memóriából a CPU két regiszterébe kell tenni.
Íme néhány példa azokra a tipikus utasításokra, amelyeket az M1-en található RISC CPU hajt végre.
load r1, 150
load r2, 200
add r1, r2
store r1, 310
Itt "r1" és "r2" azok a regiszterek, amelyekről beszéltem. A modern RISC CPU-k nem tudnak műveleteket végrehajtani olyan számokkal, amelyek nem szerepelnek egy ilyen regiszterben. Például nem tud hozzáadni két számot a RAM-ban két különböző helyen levő adathoz. Ehelyett ezt a két számot külön regiszterbe kell olvasnia. Ebben az egyszerű példában ezt tesszük. A RAM 150-es memóriahelyén lévő számot beolvassuk és a CPU "r1" regiszterébe helyezzük. Ezután a 200-as cím tartalmát az "r2" regiszterbe helyezzük. Csak ezután lehet a számokat összeadni az "add r1, r2" utasítással.
A regiszter fogalma régi. Például ezen a régi mechanikus számológépen a regiszter az, ami tartalmazza a hozzáadni kívánt számokat. Valószínűleg a pénztárgéptől ered a kifejezés. A cash register az a hely, ahol a bemeneti számokat regisztrálta.
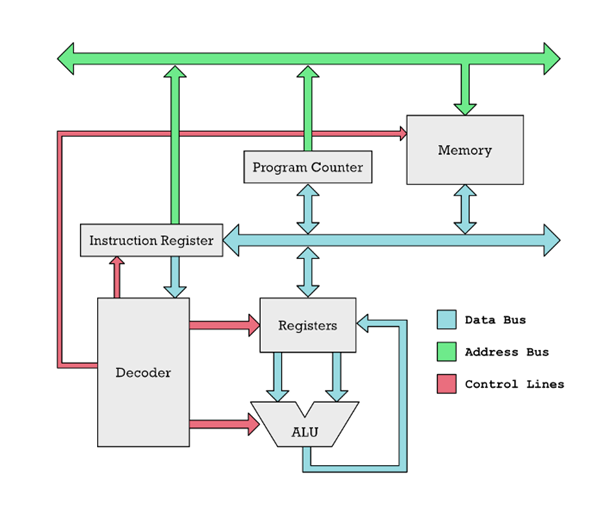
Egy nagyon egyszerű RISC CPU, nem az M1. Az utasítások a memóriából a kék nyilak mentén átkerülnek az utasításregiszterbe. Ott egy dekóder kitalálja, mi az utasítás, és a piros vezérlővonalakon keresztül engedélyezi a CPU különböző részei működését. Az ALU összeadja és kivonja a regiszterekben elhelyezett számokat.

Egy régi mechanikus számológép két regiszterrel: az akkumulátorral és a bemeneti regiszterrel. A modern CPU-k általában több mint egy tucatnyi regiszterrel rendelkeznek, és inkább elektronikusak, mint mechanikusak.

Az M1 egy chipen lévő rendszer. Ez azt jelenti, hogy a számítógépet alkotó összes alkatrész egy szilícium chipre van helyezve.

Példa a számítógép alaplapra. Memória, CPU, grafikus kártyák, IO vezérlők, hálózati kártyák és sok más alkatrész csatlakoztatható az alaplaphoz, hogy kommunikálni tudjanak egymással.
Az M1 nem CPU!
Itt van egy nagyon fontos dolog, amit meg kell érteni az M1-gyel kapcsolatban:
Az M1 nem CPU, hanem több chipből álló egész rendszer, amely egyetlen nagy szilíciumcsomagba kerül. A CPU csak egy ezek közül a chipek közül.
Alapvetően az M1 egy egész számítógép egy chipben. Az M1 tartalmaz egy CPU-t, grafikus feldolgozó egységet (GPU), memóriát, bemeneti és kimeneti vezérlőket, és még sok más dolgot, amelyek egy teljes számítógépet alkotnak. Ezt úgy hívjuk, rendszer egy chipben / System on a Chip (SoC).
Ha ma vásárol egy chipet – akár az Inteltől, akár az AMD-től – valójában egy csomó mikroprocesszort kap egy tokban. A múltban a számítógépek több, egymástól fizikailag különálló chipből épültek a számítógép alaplapján.
Mivel azonban manapság olyan sok tranzisztort tudunk egy szilíciumlemezre helyezni, az olyan vállalatok, mint az Intel és az AMD, több mikroprocesszort kezdtek el egyetlen chipre helyezni. Ma ezeket a chipeket CPU magoknak nevezzük. Egy mag alapvetően egy teljesen független chip, amely képes utasításokat olvasni a memóriából és számításokat végezni.
Hosszú ideig ez volt a játék a teljesítmény növelésére: adjunk hozzá több általános célú CPU magot. De zavar van az erőben. A CPU-piacon van egy olyan szereplő, amely eltér ettől a tendenciától.
Az Apple nem annyira titkos heterogén számítási stratégiája
Ahelyett, hogy egyre több általános célú CPU magot adna hozzá, az Apple egy másik stratégiát követett: egyre több speciális chipet kezdtek hozzáadni néhány speciális feladat elvégzésére. Ennek az az előnye, hogy a speciális chipek általában lényegesen gyorsabban tudják ellátni feladataikat sokkal kevesebb elektromos áram felhasználásával, mint egy általános célú CPU mag.
Ez nem teljesen új tudás. Az Nvidia és az AMD grafikus kártyákban már sok éve olyan speciális chipek helyezkednek el, mint a grafikus feldolgozó egységek (GPU-k), amelyek sokkal gyorsabban hajtanak végre grafikával kapcsolatos műveleteket, mint az általános célú CPU-k.
Az Apple egyszerűen radikálisabb elmozdulást tett ebbe az irányba. Ahelyett, hogy csak általános célú magokkal és memóriával rendelkezne, az M1 speciális chipek széles választékát tartalmazza:
- Központi feldolgozó egység (CPU) – a SoC „agya”. Az operációs rendszer és az alkalmazások kódjának nagy részét futtatja.
- Grafikus feldolgozó egység (GPU) – a grafikával kapcsolatos feladatokat kezeli, mint például az alkalmazás felhasználói felületének megjelenítése és a 2D/3D játékok.
- Képfeldolgozó egység (ISP) – a képfeldolgozó alkalmazások által végzett gyakori feladatok felgyorsítására használható.
- Digitális jelfeldolgozó (DSP) – matematikailag intenzívebb funkciókat kezel, mint egy CPU. Ide tartozik a zenei fájlok kicsomagolása.
- Neurális feldolgozó egység (NPU) – csúcskategóriás okostelefonokban használják a gépi tanulási (A.I.) feladatok felgyorsítására. Bele tartozik a hangfelismerés és a kamerafeldolgozás.
- Videokódoló/dekódoló – kezeli a videofájlok és -formátumok energiahatékony átalakítását.
- Secure Enclave – titkosítás, hitelesítés és biztonság
- Egységes memória – lehetővé teszi a CPU, a GPU és más magok számára az információ gyors cseréjét.
Részben ez az oka annak, hogy sokan, akik az M1 Mac-ekkel kép- és videószerkesztéssel dolgoznak, ilyen sebességnövekedést tapasztalnak. Sok feladatuk közvetlenül speciális hardveren futhat. Ez az, ami lehetővé teszi egy olcsó M1 Mac Mini számára, hogy izzadság nélkül kódoljon egy nagy videofájlt, miközben egy drága iMac minden ventillátora teljes gőzzel működik, és még mindig nem tudja tartani a lépést.
(További információ a heterogén számítástechnikáról: Az Apple M1 előrevetíti a RISC-V felemelkedését.)
Mikrochip több CPU maggal.
Kék színnel azt látja, hogy több CPU mag hozzáfér a memóriához, zölden pedig azt, hogy nagyszámú GPU mag hozzáfér a memóriához.

A CPU-knak nincs szükségük sok adatszolgáltatásra, de gyorsan akarják.

GPU-ja így akarja a memóriáját: hatalmas adagokat. Minél több, annál jobb.
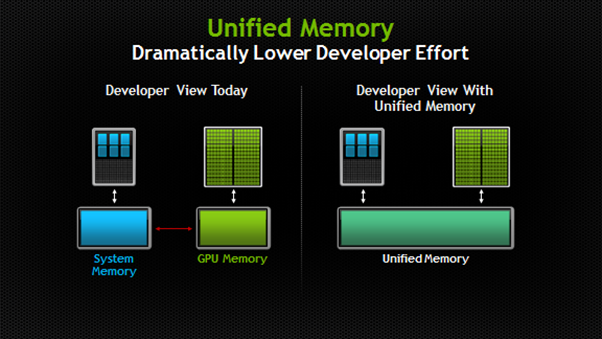
Mi a különleges az Apple egységes memóriaarchitektúrájában?
Az Apple „Unified Memory Architecture” (UMA) lényegét kicsit körülményes megérteni (amikor először leírtam ide, el is tévesztettem).
Hogy megmagyarázzuk, miért, néhány lépést vissza kell mennünk.
Az olcsó számítógépes rendszerekben hosszú ideje a CPU és a GPU ugyanabba a chipbe van integrálva (ugyanaz a szilícium lapka). Ezek híresen lassúak voltak. A múltban az „integrált grafika” kifejezés lényegében ugyanaz volt, mint a „lassú grafika”.
Ezek több okból is lassúak: A memóriának külön területei vannak fenntartva a CPU és a GPU számára. Ha a CPU-nak van egy olyan adattömbje, amelyet a GPU használni akar, akkor nem mondhatja, hogy „használd a memóriámból”. Nem, a CPU-nak kifejezetten át kellett másolnia a teljes adattömeget a GPU által vezérelt memóriaterületre.
A CPU-k és a GPU-k nem akarják, hogy a memóriájuk ugyanúgy működjön. Tegyünk egy ostoba ételhasonlatot: a CPU-k azt szeretnék, ha a pincér nagyon gyorsan kiszolgálná az adattáblájukat, de teljesen elégedettek kis adagokkal. Képzeljen el egy divatos francia éttermet görkorcsolyázó pincérekkel, akik nagyon gyorsan kiszolgálják Önt.
Ezzel szemben a GPU-k elégedettek, ha a pincér lassan szolgálja ki az adatokat. De a GPU-k hatalmas adagokat akarnak. Hatalmas mennyiségű adatot zabálnak fel, mert hatalmas párhuzamos gépek, amelyek párhuzamosan rengeteg adatot tudnak átrágni. Képzeljen el egy amerikai gyorséttermi helyet, ahol az étel megérkezése eltart egy ideig, mert egy egész kocsi ételt tolnak az ülőhelyére.
Ilyen eltérő igények mellett nem volt jó ötlet a CPU-kat és a GPU-kat egy fizikai chipre helyezni. A GPU-k ott ültek éhezve, miközben kis francia adagokat kaptak. Az eredmény az volt, hogy nincs értelme erős GPU-kat rakni egy SoC-re. A kiszolgált adatok apró részeit könnyen elrághatja egy gyenge kis GPU.
A második probléma az volt, hogy a nagy GPU-k sok hőt termelnek, és így nem lehet integrálni őket a CPU-val anélkül, hogy gond nélkül megszabadulnának a termelt hőtől. Így a különálló grafikus kártyák általában úgy néznek ki, mint az alábbi: Nagy vadállatok hatalmas hűtőventilátorokkal. Speciális dedikált memóriájuk van, amelyet arra terveztek, hogy hatalmas mennyiségű adatot szolgáltasson a mohó kártyák számára.
Ezért ezek a kártyák nagy teljesítményűek. De van egy Achilles-sarkuk: Amikor adatokat kell lekérniük a CPU által használt memóriából, ez a számítógép alaplapján lévő réz vezetékek egy PCIe busznak nevezett csoportján keresztül történik. Próbálj vizet inni egy szupervékony szívószálon keresztül. Lehet, hogy gyorsan a szádhoz jut, de az áteresztőképesség egyáltalán nem megfelelő.
Az Apple "Unified Memory Architecture" igyekszik megoldani ezeket a problémákat a régi megosztott memória hátrányai nélkül. Ezt a következő módokon éri el:
1. Nincs külön terület, amely csak a CPU-nak, vagy csak a GPU-nak van fenntartva. A memória mindkét processzorhoz le van foglalva. Mindkettő ugyanazt a memóriát használhatja. Nincs szükség másolásra.
2. Az Apple olyan memóriát használ, amely egyszerre szolgálja ki a nagy mennyiségű adatot és ugyanakkor gyorsan kiszolgálja. A számítógépes beszédben ezt alacsony késleltetésnek és nagy áteresztőképességnek nevezik. Így megszűnik a külön típusú memória csatlakoztatásának szükségessége.
3. Az Apple csökkentette a GPU watt felhasználását, így egy viszonylag erős GPU integrálható a SoC túlmelegedése nélkül. Az ARM chipek pedig kevesebb hőt termelnek, ami lehetővé teszi, hogy a GPU-nak nagyobb fűtési költségkerete legyen, mint az AMD vagy Intel CPU-val azonos szilíciumlapon lévő GPU-nak.
Egyesek azt mondják, hogy az egységes memória nem teljesen új. Igaz, hogy a múltban különböző rendszerekben volt ilyen. De akkor a memóriaigények különbsége nem lehetett olyan nagy. Másodszor, amit az Nvidia Unified Memory-nak nevez, az valójában nem ugyanaz. Az Nvidia világában a Unified Memory egyszerűen azt jelenti, hogy létezik olyan szoftver és hardver, amely gondoskodik az adatok automatikus oda-vissza másolásáról a különálló CPU és GPU memória között. Így a programozók szemszögéből az Apple és az Nvidia Unified Memory ugyanúgy nézhet ki, de fizikai értelemben nem ugyanaz.
Természetesen van egy kompromisszum ebben a stratégiában. Ennek a nagy sávszélességű memóriának a megszerzése (nagy adagok) teljes integrációt igényel, ami azt jelenti, hogy elveszi az ügyfelektől a memória bővítésének lehetőségét. Az Apple azonban arra törekszik, hogy minimalizálja ezt a problémát azáltal, hogy annyira felgyorsítja a kommunikációt az SSD-lemezekkel, hogy azok lényegében úgy működjenek, mint a régi memória.

GeForce RTX 3080
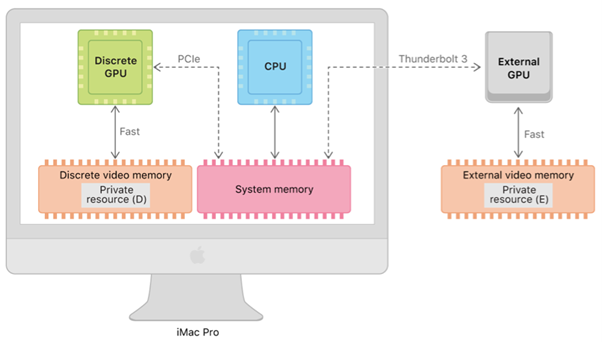
Hogyan használta a Mac a GPU-kat az egységes memória előtt. Még arra is lehetőség volt, hogy a grafikus kártyákat a számítógépen kívül helyezzék el Thunderbolt 3 kábellel. Vannak olyan feltételezések, hogy ez a jövőben is lehetséges.

AMD Ryzen Accelerated Processing Unit (APU), amely egyesíti a CPU-t és a GPU-t (Radeon Vega) egyetlen szilícium chipen. Nem tartalmaz azonban más társprocesszorokat, IO-vezérlőket vagy egyesített memóriát.

TSMC félvezetőöntöde Tajvanon. A TSMC más cégek, például az AMD, az Apple, az Nvidia és a Qualcomm számára gyárt chipeket.
Ha az SoC-k olyan okosak, miért nem másolja le az Intel és az AMD ezt a stratégiát?
Ha olyan okos, amit az Apple csinál, miért nem csinálja mindenki? Vannak akik csinálják. Más ARM chipgyártók egyre gyakrabban használnak speciális hardvert. Az AMD emellett elkezdett erősebb GPU-kat helyezni egyes chipjeire, és fokozatosan elmozdult a SoC valamilyen formája felé a gyorsított feldolgozóegységekkel (APU), amelyek alapvetően CPU-magok és GPU-magok ugyanazon a szilíciumlapon elhelyezve.
Ennek ellenére fontos okai vannak annak, hogy miért nem tudják ezt megtenni. Az SoC lényegében egy teljes számítógép egy chipen. Ez inkább a tényleges számítógép-gyártóknak lehetősége, például a HP és a Dell számára. Hadd világítsam meg egy ostoba autós hasonlattal: Ha az Ön üzleti modellje autómotorok gyártása és értékesítése, szokatlan lépés lenne egész autók gyártásába és értékesítésébe kezdenie.
Ezzel szemben az ARM esetében ez nem probléma. Az olyan számítógépgyártók, mint a Dell vagy a HP, egyszerűen licencelhetnék az ARM szellemi tulajdonát, és vásárolhatnának licenceket más chipekhez, hogy hozzáadhassanak bármilyen speciális hardvert, amiről úgy gondolják, hogy a SoC megoldásuknak rendelkeznie kell. Ezután a kész tervet egy olyan félvezetőöntödébe szállítják, mint a GlobalFoundries vagy a TSMC, amely ma chipeket gyárt az AMD és az Apple számára.
Itt van egy nagy probléma az Intel és az AMD üzleti modelljével. Üzleti modelljeik általános célú CPU-k eladásán alapulnak, amelyeket az emberek egyszerűen egy nagy PC-alaplapra helyeznek. Így a számítógépgyártók egyszerűen megvásárolhatják az alaplapokat, a memóriákat, a CPU-kat és a grafikus kártyákat különböző gyártóktól, és integrálhatják őket egyetlen megoldásba.
De gyorsan eltávolodunk ettől a világtól. Az új SoC-világban nem állítanak össze fizikai alkatrészeket különböző gyártóktól. Ehelyett különböző gyártóktól származó licenceket (szellemi tulajdont) állítanak össze. A grafikus kártyák, CPU-k, modemek, IO-vezérlők és egyéb dolgok dizájnját vásárolja meg különböző beszállítóktól, és ezt használja fel házon belüli SoC tervezésére. Ezután keres egy öntödét, amely ezt legyártja.
Itt van az igazi probléma, mert sem az Intel, sem az AMD, sem az Nvidia nem fogja licencelni a szellemi tulajdonát a Dell-nek vagy a HP-nak, hogy SoC-ot készítsenek a gépeikhez.
Az biztos, hogy az Intel és az AMD egyszerűen elkezdhetné teljesen kész SoC értékesítését. De mit is tartalmazhatnak ezek? A PC-gyártóknak eltérő elképzeléseik lehetnek arról, hogy mit kell tartalmazniuk. Lehetséges, hogy konfliktus alakul ki az Intel, az AMD, a Microsoft és a PC-gyártók között azzal kapcsolatban, hogy milyen speciális chipeket kell beletenni, mert ezekhez szoftveres támogatásra lesz szükség.
Az Apple számára ez egyszerű. Ők tartják kézben az egész palettát. Például megadják a Core ML könyvtárat a fejlesztőknek, hogy gépi tanulási dolgokat írhassanak. A fejlesztőknek nem kell törődniük azzal, hogy a Core ML az Apple CPU-ján vagy a Neural Engine-en fut-e.
A CPU gyors működésének alapvető kihívása
Tehát a heterogén számítástechnika az ok része, de nem az egyetlen oka. Az M1 gyors, általános célú CPU magjai, az úgynevezett Firestorm, valóban gyorsak. Ez jelentős eltérés az ARM CPU magoktól a múltban, amelyek általában nagyon gyengék voltak az AMD és Intel magokhoz képest.
Ezzel szemben a Firestorm legyőzi a legtöbb Intel magot, és majdnem a leggyorsabb AMD Ryzen magokat is. A hagyományos bölcsesség szerint ez nem történhet meg.
Mielőtt arról beszélnénk, hogy mitől gyors a Firestorm, nézzük meg, miről is szól valójában a gyors CPU létrehozásának alapötlete. Elvileg két stratégia kombinációjával érhető el:
1. Gyorsabban hajtson végre több utasítást egymás után.
2. Végezzen sok utasítást párhuzamosan.
A 80-as években ez könnyű volt. Csak növelje az órajel frekvenciáját, és az utasítások gyorsabban befejeződnek. Minden óraciklus az, amikor a számítógép csinál valamit. De ez a valami nagyon kevés lehet. Így egy utasítás befejezéséhez több óraciklusra lehet szükség, mivel több kisebb feladatból áll.
Az órajel frekvenciájának növelése azonban ma szinte lehetetlen. Ez az egész „Moore-törvény vége”, amelyen az emberek immár több mint egy évtizede agyalnak.
Tehát valójában a lehető legtöbb utasítás párhuzamos végrehajtásáról van szó.

Az Ampere Altra Max ARM CPU 128 maggal, felhőalapú számítástechnikához, ahol a sok hardverszál előnyt jelent.
Többmagos vagy Out-of-Order processzorok?
Ennek két megközelítése van.
- Adjon hozzá több CPU magot. Mindegyik mag önállóan és párhuzamosan működik.
- Minden CPU mag több utasítást hajtson végre párhuzamosan.
Egy szoftverfejlesztő számára a magok hozzáadása olyan, mint a szálak hozzáadása. Minden CPU mag olyan, mint egy hardverszál.
Ha nem tudja, mi az a szál, akkor képzelje el úgy, mint egy feladat végrehajtásának a folyamatát. Két maggal a CPU két külön feladatot tud egyszerre végrehajtani: két szálon. A feladatok leírhatók úgy, hogy két különálló program tárolja a memóriában, vagy valójában ugyanaz a program, amelyet kétszer hajtanak végre. Minden szálnak szüksége van némi könyvelésre, például arra, hogy a szál a program utasítások sorozatában éppen hol tart. Mindegyik szál tárolhat ideiglenes eredményeket, amelyeket elkülönítve kell tartani.
Elvileg egy processzornak csak egy magja lehet, és több szálat is futtathat. Ebben az esetben egyszerűen leállítja az egyik szálat, és eltárolja az aktuális folyamatot, mielőtt egy másikra váltana. Később visszakapcsol. Ez nem hoz nagy teljesítménynövekedést, kivéve, ha a szálnak gyakran le kell állnia, hogy:
- megvárja a felhasználó reagálását
- lassú hálózati kapcsolatból megérkezzenek adatok stb.
Nevezzük ezeket szoftverszálaknak. A hardverszálak azt jelentik, hogy tényleges fizikai CPU-magok állnak az Ön rendelkezésére a dolgok felgyorsítása érdekében.
A probléma a szálakkal az, hogy a szoftverfejlesztőknek úgynevezett többszálú kódot kell írniuk. Ez gyakran nehéz. A múltban ez volt a legnehezebb kód megírása. A szerverszoftver többszálúvá tétele azonban általában könnyebb. Egyszerűen arról van szó, hogy minden felhasználói kérést külön szálon kell kezelni. Így ebben az esetben a sok mag használata nyilvánvaló előny. Főleg a felhőszolgáltatásoknál.
Ez az oka annak, hogy az ARM CPU-gyártók, mint például az Ampere olyan CPU-kat gyártanak, mint az Altra Max, amelynek őrült mennyiségű, 128 magja van. Ez a chip kifejezetten a felhőhöz készült. Egyébként nincs szükség őrült egymagos teljesítményre, mert a felhőben az a lényeg, hogy wattonként a lehető legtöbb szál legyen, hogy minél több egyidejű felhasználót lehessen kezelni.
(További információ a sok maggal rendelkező ARM CPU-król: A szerverek a következők az Apple számára?)
Ezzel szemben az Apple a spektrum teljesen ellenkező végén található. Egyfelhasználós eszközöket gyártanak. A sok szál nem előny. Eszközeiket játékra, videószerkesztésre, fejlesztésre stb. használják. Gyönyörű reszponzív grafikával és animációkkal rendelkező asztali számítógépeket szeretnének.
Az asztali szoftverek általában nem sok mag felhasználására készültek. Például a számítógépes játékok valószínűleg hasznot húznak a nyolc magból, de valami 128 mag teljes pazarlás lenne. Ehelyett kevesebb, de erősebb magra lenne szükség.
Hogyan működik a Out-of-Order Execution
Erősebb maghoz több utasítás párhuzamos végrehajtására van szükségünk. A soron kívüli végrehajtás (OoOE) több utasítás párhuzamos végrehajtásának módja anélkül, hogy ezt a képességet több szálként kezelnénk.
(Alternatív megoldásért olvassa el: Nagyon hosszú utasítású szó mikroprocesszorok)
A fejlesztőknek nem kell kifejezetten úgy kódolniuk szoftverüket, hogy kihasználják az OoOE előnyeit. A fejlesztő szemszögéből nézve úgy tűnik, hogy minden mag gyorsabban fut. Vegyük figyelembe, hogy ez nem a hardverszálak közvetlen alternatívája. Mindkettőt szeretné használni, a megoldandó problémától függően.
Az OoOE működésének megértéséhez tudnunk kell néhány dolgot a memóriával kapcsolatban. Az adatok lekérése egy adott memóriahelyen lassú. De a CPU képes egyszerre sok bájtot fogadni. Ennélfogva 1 adott bájt memóriába kerülése nem vesz kevesebb időt igénybe, mint 100 további bájt beírása a memóriába.
Íme egy analógia: Vegye figyelembe a rakodókat egy raktárban. Lehetnek a kis piros robotok a fenti képen. A több, szétszórt helyre való közlekedés időbe telik. De az egymás melletti nyílásokból gyorsan felveszi az elemeket. A számítógép memóriája nagyon hasonló. Gyorsan lekérheti a szomszédos memóriacellák tartalmát.
Az adatokat az úgynevezett adatbuszon keresztül továbbítják. Úgy képzelheti el, mint egy út vagy cső a memória és a CPU különböző részei között, ahol az adatok átjutnak. A valóságban természetesen csak néhány rézsín vezeti az áramot. Ha az adatbusz elég széles, akkor több bájtot is kaphat egyszerre.
Így a CPU-k egyszerre egy egész utasításcsomagot kapnak végrehajtásra. De arra vannak megírva, hogy egyenként, egymás után végezzék el. A modern mikroprocesszorok az úgynevezett Out-of-Order végrehajtást (OoOE) végzik.
Ez azt jelenti, hogy képesek gyorsan elemezni az utasítások pufferét, és megnézni, hogy melyik függ a másiktól. Nézze meg az alábbi egyszerű példát:
01: mul r1, r2, r3 // r1 ← r2 × r3
02: add r4, r1, 5 // r4 ← r1 + 5
03: add r6, r2, 1 // r6 ← r2 + 1
A szorzás általában lassú folyamat. Tegyük fel, hogy több órajel alatt lehet végrehajtani. A második utasításnak egyszerűen várnia kell, mert a számítása attól függ, hogy ismerjük-e az r1 regiszterbe kerülő eredményt.
A 03. sorban lévő harmadik utasítás azonban nem függ a korábbi utasítások számításaitól. Így egy Out-of-Order processzor párhuzamosan elkezdheti kiszámítani ezt az utasítást.
Reálisabban azonban több száz utasításról beszélünk. A CPU képes kitalálni az összes függőséget ezen utasítások között.
Az utasításokat az egyes utasítások bemeneteinek megtekintésével elemzi. Függnek a bemenetek egy vagy több másik utasítás kimenetétől? Bemeneten és kimeneten a korábbi számítások eredményeit tartalmazó regisztereket értjük.
Például az "add r4, r1, 5" utasítás az r1 bemenetétől függ, amelyet a "mul r1, r2, r3" állít elő. Ezeket a kapcsolatokat hosszú, kidolgozott grafikonokba láncolhatjuk, amelyeken a CPU képes dolgozni. A csomópontok az utasítások, az élek pedig az őket összekötő regiszterek.
A CPU képes elemezni a csomópontok ilyen grafikonját, és meghatározni, hogy mely utasításokat hajthatja végre párhuzamosan, és hol kell megvárnia több függő számítás eredményét, mielőtt folytatná.
Sok utasítás korán befejeződik, de nem tudjuk hivatalossá tenni az eredményeket. Nem tudjuk véglegesíteni őket; ellenkező esetben az eredményt rossz sorrendben adjuk meg. A világ többi része számára úgy kell kinéznie, mintha az utasításokat ugyanabban a sorrendben hajtották volna végre, mint ahogyan azokat kiadták.
Mint egy verem, a CPU folyamatosan kiveszi a kész utasításokat felülről, amíg el nem talál egy olyan utasítást, amely nem történt meg.
A párhuzamosságnak alapvetően két formája van: az egyik, amellyel a fejlesztőnek kifejezetten foglalkoznia kell a kód írásakor, a másik pedig teljesen láthatatlan. Ez utóbbi természetesen sok tranzisztorra támaszkodik a CPU-ban, amelyet az Out-of-Order Execution varázslatnak szenteltek. Ez kevés tranzisztorral rendelkező CPU-k számára nem életképes megoldás.
Ez a kiváló Out-of-Order végrehajtás teszi a Firestorm magokat az M1-ben verhetetlenné. Valójában sokkal erősebb, mint bármi az Inteltől vagy az AMD-től, és lehet, hogy soha nem fogják utolérni. Ahhoz, hogy megértsük miért, további technikai részletekbe kell belemennünk.

Robot rakodók a raktárban a Komplett.no norvég online áruháznál.
ISA utasítások vs mikroműveletek
Kihagytam néhány részletet az Out-of-Order Execution (OoOE) működésével kapcsolatban.
A memóriába betöltött programok gépi kódú utasításokból állnak, amelyeket speciális utasításkészlet-architektúrákhoz (ISA) terveztek, mint például az x86, ARM, PowerPC, 68K, MIPS, AVR stb.
Például az x86 utasítás egy szám lekérésére a 24-es memóriahelyről egy regiszterbe:
MOV ax, 24
Az x86-nak ax, bx, cx és dx nevű regiszterei vannak (ne feledje, hogy ezek a memóriacellák a CPU-n belül, amelyeken műveleteket hajt végre). Az egyenértékű ARM utasítás azonban így nézne ki:
LDR r0, 24
Az AMD és az Intel processzorok megértik az x86 ISA utasításokat, míg az Apple Silicon chipek, például az M1, megértik az ARM Instruction-Set Architecture-t (ISA).
Azonban belül a CPU egy teljesen más, a programozó számára láthatatlan utasításkészleten működik. Ezeket mikroműveleteknek (micro-ops vagy μops) nevezzük. Ezekkel az utasításokkal működik az Out-of-Order Execution hardver.
De miért nem működik az OoOE hardver normál gépi kód utasításokkal? Mivel a CPU-nak sok különböző információt kell csatolnia az utasításokhoz, hogy párhuzamosan fusson. Így míg egy normál ARM utasítás lehet 32 bites (32 0 és 1 számjegy), addig a mikrooperáció sokkal hosszabb lehet. A sorrendjével kapcsolatos információkat tartalmaz.
01: mul r1, r2, r3 // r1 ← r2 × r3
02: add r4, r1, 5 // r4 ← r1 + 5
03: add r1, r2, 1 // r1 ← r2 + 1
Mi van, ha párhuzamosan futtatjuk a "01: mul" és "03: add" utasításokat. Mindkettő az r1 regiszterben tárolja az eredményét. Ha a "03: add" utasítás eredményét írjuk a "01: mul" elé, akkor a "02: add" utasítás rossz bemenetet kap. Ezért nagyon fontos nyomon követni az utasítások sorrendjét. A sorrendet minden egyes mikro-opnál tároljuk. Tárolódik még pl. hogy a "02: add" utasítás a "01: mul" kimenetétől függ.
Emiatt nem írhatunk programokat micro-ops segítségével. Rengeteg részletet tartalmaznak az egyes mikroprocesszorok belső tulajdonságaira vonatkozóan. Két ARM processzor belül nagyon eltérő mikroműveletekkel rendelkezhet.
(További információ a mikroműveletekhez hasonló utasításokkal rendelkező CPU-król: Nagyon hosszú utasítású Word mikroprocesszorok.)
Ezenkívül a mikroműveletekkel általában könnyebb dolgozni a CPU-nak. Miért? Mert mindegyik egy egyszerű, korlátozott feladatot végez. A szokásos ISA-utasítások bonyolultabbak lehetnek, ami egy csomó feladatot okozhat, és így gyakran több mikroműveletté alakul. Így a „mikro” név az általuk elvégzett kis feladatból ered, nem pedig a memóriában lévő utasítás hosszából.
A CISC CPU-k esetében általában nincs más megoldás, mint a mikroműveletek használata, különben a nagy, összetett CISC utasítások szinte lehetetlenné tennék a csővezetékek és az OoOE megvalósítását.
(Bővebben: Miért használjunk mikroprocesszort?)
A RISC CPU-k választhatnak. Így például a kisebb ARM CPU-k egyáltalán nem használnak mikroműveleteket. De ez azt is jelenti, hogy nem tehetnek olyan dolgokat, mint az OoOE.
Miért rosszabb az AMD és az Intel Out-of-Order végrehajtása, mint az M1?
De vajon miért számít mindez? Miért fontos tudni ezt a részletet, hogy megértsük, miért van az Apple fölényben az AMD-vel és az Intellel szemben?
Azért van így, mert a gyors futás képessége attól függ, hogy milyen gyorsan tudják feltölteni a mikroműveletek pufferét. Ha nagy pufferrel rendelkezik, akkor az OoOE hardver könnyebben meg tudja találni azt a két vagy több utasítást, amelyeket párhuzamosan tud futtatni. De nincs értelme egy nagy utasításpuffernek, ha nem tudja elég gyorsan újratölteni az utasítások kiválasztása és végrehajtása után.
Az utasításpuffer gyors újratöltésének sebessége azon a képességen múlik, hogy a gépi kód utasításait gyorsan mikroműveletekre lehet vágni. Azokat a hardveregységeket, amelyek ezt végzik, dekódereknek nevezzük.
És végül elérkeztünk az M1 gyilkos funkciójához. A legnagyobb és legjelentősebb Intel és AMD mikroprocesszorban összesen négy dekóder van, amelyek a gépi kód utasításait mikro-műveletekre vágják.
De ez nem így van az M1-ben, amelynek hallatlanul sok dekódere van: nyolc. Lényegesen több, mint bárki másnak az iparágban. Ez azt jelenti, hogy sokkal gyorsabban meg tudja tölteni az utasításpuffert.
Ennek kezelésére az M1-nek van egy utasításpuffere is, amely háromszor nagyobb, mint az iparágban megszokott.
Miért nem tud az Intel és az AMD több utasítás-dekódert hozzáadni?
Itt láthatjuk végre a RISC bosszúját, és itt kezd számítani az a tény, hogy az M1 Firestorm mag ARM RISC architektúrával rendelkezik.
Egy x86-os utasítás 1–15 bájt hosszúságú lehet. A RISC utasítások fix hosszúságúak. Minden ARM utasítás 4 bájt hosszú. Miért releváns ez ebben az esetben?
Mert egy bájtfolyam felosztása utasításokra, amelyek párhuzamosan nyolc különböző dekóderbe táplálhatók be, triviálissá válik, ha minden utasítás azonos hosszúságú.
Az x86-os CPU-n azonban a dekódereknek fogalmuk sincs, hol kezdődik a következő utasítás. Valójában elemeznie kell az egyes utasításokat, hogy lássa, milyen hosszúak.
Az Intel és az AMD a brutális erővel kezeli ezt azáltal, hogy minden lehetséges kiindulási pontnál egyszerűen megpróbálja dekódolni az utasításokat. Ez azt jelenti, hogy az x86-os chipeknek sok rossz találgatással és hibával kell megküzdeniük, amelyeket el kell dobni. Ez olyan nehézkes és bonyolult dekódoló szakaszt hoz létre, hogy nagyon nehéz több dekódert hozzáadni. De az Apple számára ehhez képest triviális, hogy adjon hozzá többet.
Valójában a további dekóder hozzáadása annyi más problémát okoz, hogy az AMD szerint négy dekóder alapvetően felső határt jelent számukra.
Ez az, ami lehetővé teszi, hogy az M1 Firestorm magok lényegében kétszer annyi utasítást dolgozzanak fel, mint az AMD és az Intel CPU-k ugyanazon az órajelen.
Ellenpontként lehetne vitatkozni azzal, hogy a CISC-utasítások több mikroműveletté válnak. Például, ha minden x86-os utasítás 2 micro-op-ba fordult, míg minden ARM utasítás 1 mikroműveletté alakult, addig négy x86-os dekóder órajelenként ugyanannyi mikroműveletet produkál, mint egy ARM CPU 8 dekóderrel.
Csakhogy ez a való világban nem így van. A nagymértékben optimalizált x86 kód ritkán használ összetett CISC utasításokat, amelyek sok mikroműveletet eredményeznének. Valójában a legtöbb csak 1 mikroműveletté válik.
Mindezek az egyszerű x86-os utasítások azonban nem segítenek az Intelnek vagy az AMD-nek. Mert még ha ritkák is ezek a 15 bájtos utasítások, a dekódereknek kezelni kell őket. Ez olyan összetettséggel jár, amely megakadályozza, hogy az AMD és az Intel több dekódert adjon hozzá.
De az AMD Zen3 magjai még mindig gyorsabbak, igaz?
Ha jól emlékszem a teljesítmény-benchmarkokból, a legújabb AMD CPU magok, a Zen3 nevűek valamivel gyorsabbak, mint a Firestorm magok. De itt van a felütés: ez csak azért történik, mert a Zen3 magok órajele 5 GHz. A Firestorm magok órajele 3,2 GHz. A Zen3 alig szorítja túl a Firestormot annak ellenére, hogy majdnem 60%-kal magasabb órajel frekvenciája van.
Akkor miért nem növeli az Apple az órajel frekvenciáját is? Mivel a magasabb órajel-frekvencia miatt a chipek melegebbek lesznek. Ez az Apple egyik legfontosabb értékesítési pontja. Számítógépeik – az Intel és az AMD kínálatával ellentétben – alig igényelnek hűtést.
Lényegében azt mondhatjuk, hogy a Firestorm magok valóban jobbak a Zen3 magoknál. A Zen3 csak úgy tud benne maradni a játékban, hogy sokkal több áramot vesz fel, és sokkal melegebb lesz. Valamit az Apple egyszerűen úgy dönt, hogy nem teszi meg.
Ha az Apple nagyobb teljesítményt szeretne, egyszerűen csak több magot ad hozzá. Ez lehetővé teszi számukra, hogy csökkentsék a wattfogyasztást, miközben nagyobb teljesítményt nyújtanak.
A jövő
Úgy tűnik, az AMD és az Intel két fronton is sarokba állította magát: Nincs olyan üzleti modelljük, amely megkönnyítené a heterogén számítástechnikai és SoC-tervek megvalósítását. x86 CISC utasításkészletük öröksége visszatér, hogy kísértse őket, megnehezítve az OoO teljesítmény javítását.
(Bővebben: Intel, ARM és az újítók dilemmája)
x86 ellentámadások
Ez nem azt jelenti, hogy a játék véget ért. Növelhetik az órajel-frekvenciát és több hűtést használhatnak, több magot dobnak be, növelik a CPU gyorsítótárait stb. A RISC dekóder előnyei elleni küzdelem legnyilvánvalóbb módja a mikro-op gyorsítótárak használata. Ez egy speciális stratégia a CISC processzorok változó hosszúságú utasítások dekódolásának bonyolultságának leküzdésére. Egy új utasítás dekódolása előtt a CPU ellenőrizheti, hogy ugyanazt az utasítást már dekódolta-e. A legtöbb program gyakran ismétel bizonyos utasításokat (hurkok), ami azt jelenti, hogy ez elég jól működik. Így mindaddig, amíg szűk körökben futnak, visszaszerezhetik az M1-es előnyt.
A játéknak tehát még nincs vége, de azt is mutatja, hogy az AMD-nek és az Intelnek sokkal okosabb trükköket kell kitalálnia az elöregedő utasításkészlet-architektúra (ISA) által mesterségesen előidézett problémák leküzdésére.
Tehát még korántsem ért véget a játék, de az Intel és az AMD hátránnyal játssza a CPU játékot. Elöl maradhatnak, ha több pénzt költenek a problémákra, és nagyobb mennyiségben termelnek. De hogy ez mennyire lesz eredményes hosszú távon, az majd kiderül, mivel az Apple-lel kell szembenézni, amely több profitot termel, mint bármely más vállalat a világon, és hatalmas pénzkupacot tud elégetni.