
Az M1 egy paradigmaváltás kezdete, ami a RISC-V mikroprocesszorok számára előnyös lesz, de nem úgy, ahogy gondolod.
Erik Engheim, 2020. november 19.
17 perces olvasmány


A Google TPU-k alkalmazásspecifikus integrált áramkörök (ASIC). Társprocesszorként fogok hivatkozni rájuk.
Mára már teljesen világos, hogy az Apple M1 chipje nagy jelentőségű. A következmények az iparág többi részére fokozatosan egyre világosabbá válnak. Ebben a történetben a RISC-V mikroprocesszorok szerepéről szeretnék beszélni, amely a legtöbb olvasó számára nem nyilvánvaló.
Először hadd nyújtsak egy kis hátteret: Miért olyan gyors az Apple M1 chipje?
Ebben a cikkben az M1 teljesítményét befolyásoló két tényezőről írtam. Az egyik a hatalmas számú dekóder és az Out-of-Order Execution (OoOE) használata. Ne aggódjon, ha technológiai gusztustalanságnak tűnik.
Ez az írás a másik részről fog szólni: a heterogén számítástechnikáról. Az Apple agresszíven törekszik arra a stratégiára, hogy speciális hardveregységeket építsen össze, amikre ebben a cikkben társprocesszorként fogok hivatkozni:
- GPU (Graphical Processing Unit) grafikus és sok más feladathoz, nagy adatpárhuzamot biztosítva (egyszerre sok elemen végezze el ugyanazt a műveletet).
- Neurális Motor (Neural Engine). Speciális hardver gépi tanuláshoz.
- Digitális jelfeldolgozó hardver képfeldolgozáshoz.
- Videó kódolás hardverben.
Ahelyett, hogy sokkal több általános célú processzort adna a megoldáshoz, az Apple sokkal több társprocesszort kezdett alkalmazni. Használhatod a gyorsítók kifejezést is.
Ez nem teljesen új trend, 1985-ből a jó öreg Amiga 1000 számítógépemben társprocesszorok voltak, hogy felgyorsítsák a hangot és a grafikát. A modern GPU-k is alapvetően társprocesszorok. A Google Tensor Processing Units a gépi tanuláshoz használt társprocesszorok egyik formája.
Mi az a társprocesszor?
A CPU-val ellentétben a társprocesszor nem élhet egyedül. Nem lehet számítógépet úgy készíteni, hogy csak egy társprocesszort ragkunk bele. A társprocesszor, speciális célú processzor, amely egy adott feladatot nagyon jól végez.
A társprocesszorok egyik legkorábbi példája az Intel 8087 lebegőpontos egység (FPU) volt. A szerény Intel 8086 mikroprocesszor képes egész számokkal számolni, de lebegőpontos aritmetikát nem tud. Mi a különbség?
Az egész számok ilyenek: 43, -5, 92, 4.
Ezekkel meglehetősen könnyű dolgozni a számítógépeken. Valószínűleg össze tudna rakni megoldást egész számok hozzáadására néhány egyszerű chippből.
A probléma akkor kezdődik, amikor tizedesjegyeket szeretne. Tegyük fel, hogy olyan számokat szeretne összeadni vagy szorozni, mint a 4,25, 84,7 vagy 3,1415.
Ezek példák a lebegőpontos számokra. Ha a pont utáni számjegyek száma rögzített, akkor ezt fixpontos számoknak neveznénk. A pénzzel gyakran így bánnak. Általában két tizedesjegy van a pont után.
A lebegőpontos aritmetika azonban emulálható egész számokkal, csak lassabb. Ez olyan, mint amikor a korai mikroprocesszorok sem tudtak egész számokat szorozni. Csak összeadni és kivonni tudtak. A szorzást azonban továbbra is el lehet végezni. Csak emulálni kellett többszörös kiegészítéssel. Például 3 × 4 egyszerűen 4 + 4 + 4.
Nem fontos megérteni az alábbi kódpéldát, de azt segíthet megérteni, hogy a CPU hogyan tud szorzást végrehajtani csak összeadás, kivonás és elágazás (kódbeugrás) használatával.
loadi r3, 0 ; Load 0 into register r3
multiply:
add r3, r1 ; r3 ← r3 + r1
dec r2 ; r2 ← r2 - 1
bgt r2, multiply ; goto multiply if r2 > 0
Röviden: mindig meg lehet oldani a bonyolultabb matematikai műveleteket egyszerűbbek ismétlésével.
Amit minden társprocesszor csinál, az ehhez hasonló. Mindig van mód arra, hogy a CPU ugyanazt a feladatot végezze el, mint a társprocesszor. Ehhez azonban általában több egyszerűbb művelet megismétlésére van szükség. A GPU-k korai beszerzésének oka az volt, hogy ugyanazon számítások megismétlése több millió sokszögen vagy pixelen valóban időigényes volt egy CPU számára.

Intel 8087. A lebegőpontos számítások elvégzésére használt korai társprocesszorok egyike.
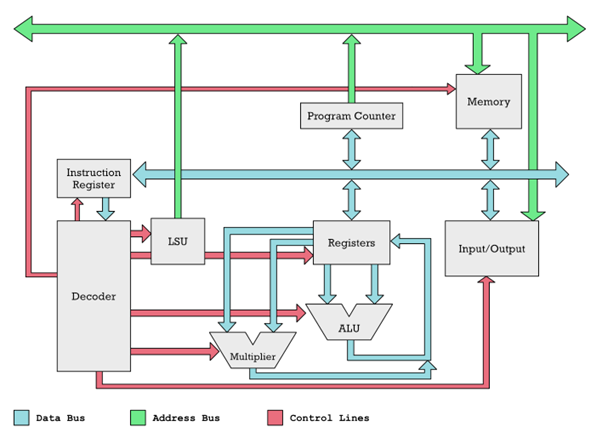
A mikroprocesszor működésének áttekintése.
Az adatbuszokat olyan csöveknek tekintheti, amelyek szelepeit a piros vezérlővonalak nyitják és zárják. Az elektronikában azonban ezt multiplexereknek nevezzük, nem pedig tényleges szelepeknek.
Hogyan történik az adatok továbbítása a társprocesszorhoz és vissza
Nézzük meg az alábbi diagramot, hogy jobban megértsük, hogyan működik együtt a társprocesszor a mikroprocesszorral (CPU), vagy ha úgy tetszik, általános célú processzorral.
A számok színes vonalak mentén mozognak. A bemenet/kimenet lehet társprocesszor, egér, billentyűzet és egyéb eszközök. A zöld és világoskék buszokat csöveknek is gondolhatjuk. A számok ezeken a csöveken keresztül jutnak el a CPU különböző funkcionális egységeihez (szürke dobozok). Ezeknek a dobozoknak a be- és kimenetei a csövekhez csatlakoznak. Az egyes dobozok bemeneteit és kimeneteit szelepeknek képzelhetjük. A piros vezérlővonalak ezeknek a szelepeknek a nyitására és zárására szolgálnak. Így a piros vonalakért felelős Dekóder kinyithat két szürke dobozon lévő szelepet, hogy számok áramoljanak közöttük.
Ez lehetővé teszi, hogy elmagyarázzuk, hogyan lehet az adatokat lekérni a memóriából. Számokkal végzett műveletek végrehajtásához szükségünk van rájuk a regiszterekben. A Dekóder a vezérlővezetékeket használja a szelepek kinyitására a szürke Memória doboz és a Regiszterek doboz között. Ez konkrétan így történik:
1. A dekóder kinyit egy szelepet a terheléstároló egységen (LSU), ami egy memóriacím kiáramlását okozza a zöld címbuszon.
2. A Memória dobozon egy másik szelep nyílik, így képes fogadni a címet a zöld csövön (címbusz). Az összes többi szelep zárva van, így pl. Az Input/Output nem tudja fogadni a címet.
3. A megadott címmel rendelkező memóriacella kerül kiválasztásra. A tartalma a kék adatbuszra folyik ki, mert a Dekóder kinyitotta az adatbusz szelepét.
4. A memóriacellában lévő adatok bárhová áramolhatnak, de a Dekóder csak a regiszterek bemeneti szelepét nyitotta meg.
Az olyan dolgok, mint az egér, a billentyűzet, a képernyő, a GPU, az FPU, a Neural Engine és más társprocesszorok, megegyeznek a bemeneti/kimeneti mezővel. Úgy érjük el őket, mint a memóriahelyeket. A merevlemezek, az egér, a billentyűzet, a hálózati kártyák, a GPU, a DMA (közvetlen memóriaelérés) és a társprocesszorok mindegyikéhez memóriacím van hozzárendelve.
A hardverek ugyanúgy adott memória címekként érhetők el
Pontosan mit értek ez alatt? Hadd találjak ki néhány címet. Ha a processzor a 84-es memóriacímről próbál olvasni, az a számítógépes egér x-koordinátáját jelentheti. Míg mondjuk a 85 az y-koordinátát jelenti. Tehát az egérkoordináták megszerzéséhez valami ilyesmit kell tennie az assembly kódba:
load r1, 84 ; get x-coordinate
loar r2, 85 ; get y-coordinate
Egy DMA vezérlő esetében előfordulhat, hogy a 110, 111 és 113 címeknek speciális jelentése van. Íme egy nem valós kód, amely ezeket használja a DMA vezérlővel való interakcióhoz:
loadi r1, 1024 ; set register r to source address
loadi r2, 50 ; bytes to copy
loadi r3, 2048 ; destination address
store r1, 110 ; tell DMA controller start address
store r2, 111 ; tell DMA to copy 50 bytes
store r3, 113 ; tell DMA where to copy 50 bytes to
Minden így működik. Speciális memóriacímekre olvas és ír. Természetesen a szokásos szoftverfejlesztők ezt soha nem látják. Ezt az eszköz illesztőprogramok végzik. A felhasználói programok csak azokat a virtuális memóriacímeket látják, ahol ez már nem jelenik meg. De az illesztőprogramok ezeket az alapvető címeket képezik le a virtuális memória címeibe.
Nem fogok túl sokat mondani a virtuális memóriáról. Lényegében valódi címeket kaptunk. A zöld buszon lévő címek virtuális címekről valós fizikai címekre lesznek fordítva. Amikor elkezdtem programozni C/C++ nyelven DOS-ban, nem volt ilyesmi. Egyszerűen beállíthattam a C pointert úgy, hogy egyenesen a videomemória memóriacímére mutasson, és elkezdhettem közvetlenül írni a kép megváltoztatásához.
char *video_buffer = 0xB8000; // set pointer to CGA video buffer
video_buffer[3] = 42; // change color of 4th pixel
A társprocesszorok ugyanúgy működnek, mint ez. A Neural Engine, a GPU, a Secure Enclave és így tovább rendelkeznek címekkel, amelyekkel kommunikálnak. Amit fontos tudni ezekről, valamint a DMA vezérlőhöz hasonló dolgokról, hogy aszinkron módon működhetnek.
Ez azt jelenti, hogy a CPU egy csomó utasítást képes elrendezni az általa megértett Neurális Motorhoz vagy GPU-hoz, és ezeket egy pufferbe írja a memóriában. Ezt követően tájékoztatja a Neurális Motort vagy a GPU társprocesszort ezen utasítások helyéről az IO-címeik megbeszélésével.
Nem akarod, hogy a CPU ott üljön és tétlenül várja, hogy a társprocesszor átrágja az összes utasítást és adatot. Ezt a DMA-val sem szeretnéd megtenni. Ezért általában biztosítunk valamilyen megszakítást.

Hogyan működik a megszakítás?
A PC-be helyezett különféle kártyákhoz, legyenek azok grafikus kártyák vagy hálózati kártyák, megszakítási vonalat rendelnek. Ez olyan vonal, amely egyenesen a CPU-hoz megy. Amikor ez a vonal aktiválódik, a CPU mindent eldob, amivel dolgozik, hogy kezelje a megszakítást.
Vagy pontosabban. A memóriában tárolja aktuális helyét és regisztereinek értékeit, így később visszatérhet bármihez, amit épp csinált.
Ezután egy úgynevezett megszakítási táblában keresi, hogy mit kell tennie. A táblában van egy olyan program címe, amelyet a megszakítás hatására futtatni szeretne.
Programozóként nem látod ezeket a dolgokat. Számodra ez inkább visszahívási funkcióknak tűnik, amelyeket bizonyos eseményekre regisztráltál. A driverek ezt általában alsó szinten kezelik.
Miért mondom el neked ezeket a hülye részleteket? Mert segít kialakítani az intuíciót arról, hogy mi történik a társprocesszorok használatakor. Ellenkező esetben nem világos, hogy a társprocesszorral való kommunikáció valójában mit jelent.
A megszakítások használatával sok dolog párhuzamosan történhet. Egy alkalmazás lekérhet képet a hálózati kártyától, miközben a CPU-t megszakítja a számítógépes egér. Az egeret elmozdították, és szükségünk van az új koordinátákra. A CPU ezeket be tudja olvasni és elküldi a GPU-nak, így az egérkurzort át tudja rajzolni az új helyre. Amikor a GPU az egérkurzort rajzolja, a CPU elkezdheti feldolgozni a hálózatról letöltött képet...
Hasonlóképpen ezekkel a megszakításokkal összetett gépi tanulási feladatokat küldhetünk az M1 Neural Engine-nek, hogy mondjuk azonosítsunk egy arcot a webkamerán. Ezzel egyidejűleg a számítógép többi része is reagál, mert a CPU által végzett minden mással párhuzamosan rágja át magát a Neurális Motor a képadatokon.
A RISC-V felemelkedése
Még 2010-ben UC Berkley-ben a Parallel Computing Laboratory tapasztalta a fejlődést a társprocesszorok fokozottabb használata felé. Látták, hogy a Moore-törvény vége azt jelenti, hogy az általános célú CPU-magokból már nem lehet könnyen nagyobb teljesítményt kicsikarni. Speciális hardverre volt szüksége: társprocesszorokra.
Gondolkozzunk el egy pillanatra, hogy miért van ez. Tudjuk, hogy az órajel frekvenciáját nem lehet egykönnyen növelni. Közel 3–5 GHz-en ragadtunk. Menj magasabbra, és a wattfogyasztás és a hőtermelés kiugrik a tetőn.
Sokkal több tranzisztort azonban tudunk hozzáadni. Egyszerűen nem tudjuk gyorsabbá tenni a tranzisztorokat. Így párhuzamosan több munkát kell végeznünk. Ennek egyik módja az, ha sok általános célú magot adunk hozzá. Rengeteg dekódert adhatunk hozzá, és soron kívüli végrehajtást végezhetünk (OoOE), amint azt korábban tárgyaltam: Miért olyan gyors az Apple M1 chipje?
Tranzisztor költségvetés: CPU magok vagy társprocesszorok?
Továbbra is játszhatunk ezzel a játékkal, és végül 128 általános magunk lesz, mint például az Ampere Altra Max ARM processzornak. De valóban ez a legjobb felhasználási módja a szilíciumunknak? A felhőben lévő szerverek számára ez nagyszerű. Valószínűleg mind a 128 magot el lehet foglalni különféle ügyfélkérésekkel. Előfordulhat azonban, hogy egy asztali rendszer nem képes hatékonyan használni 8-magnál többet a gyakori asztali munkaterheléseknél. Így, ha mondjuk 32 magra növeljük, akkor sok magra pazarolunk szilíciumot, amelyek az idő nagy részében tétlenül állnak.
Ahelyett, hogy ezt a sok szilíciumot több CPU magra költenénk, esetleg adjunk hozzá több társprocesszort?
Gondoljon erre a következőképpen: tranzisztor költségvetése van. A kezdeti időkben talán 20 000 tranzisztoros költségvetéssel rendelkezett, és úgy gondolta, hogy 15 000 tranzisztoros CPU-t készíthet. Ez közel áll a 80-as évek eleji valósághoz. Most ez a CPU talán 100 különböző feladatot tud elvégezni. Tegyük fel, hogy 1000 tranzisztorba kerül egy speciális társprocesszor elkészítése ezen feladatok egyikéhez. Ha minden feladathoz készítenél egy társprocesszort, akkor 100 000 tranzisztorhoz jutna. Ez felborítaná a költségvetését.
A tranzisztorbőség megváltozott stratégiája
A korai tervezés során az általános célú számítástechnikára kellett összpontosítani. De manapság annyi tranzisztort tömhetünk a chipekbe, hogy alig tudunk mit kezdeni velük.
Így a társprocesszorok tervezése jelentőssé vált. Sok kutatás folyik mindenféle új társprocesszor készítéséről. Ezek azonban általában elég buta gyorsítókat tartalmaznak, amelyeket ki kell szolgálni. Ellentétben a CPU-val, nem tudják elolvasni az utasításokat, amelyek elmondják nekik az összes lépést. Általában nem tudják, hogyan férhessenek hozzá a memóriához és hogyan szervezzenek bármit is.
Így a közös megoldás az, hogy egy egyszerű CPU-t használunk számukra egyfajta vezérlőként. Tehát az egész társprocesszor egy speciális gyorsítóáramkör, amelyet egy egyszerű CPU vezérel, és amely beállítja a gyorsítót, hogy elvégezze a feladatát. Általában ez nagyon speciális. Például egy Neurális Motor vagy Tenzor Feldolgozó Egység nagyon nagy regiszterekkel foglalkozik, amelyek mátrixokat (számsorokat és oszlopokat) tartalmazhatnak.
A RISC-V-t a gyorsítók vezérlésére tervezték
A RISC-V pontosan erre készült. 40-50 utasításból álló minimális utasításkészlettel rendelkezik, amely lehetővé teszi az összes tipikus CPU-feladatot. Lehet, hogy soknak hangzik, de ne feledje, hogy egy x86 CPU több mint 1500 utasítással rendelkezik.
A nagy fix utasításkészlet helyett a RISC-V-t a kiterjesztések gondolata köré tervezték. Minden társprocesszor más lesz. Így tartalmazni fog egy RISC-V processzort az alapvető utasításkészletet megvalósító műveletek kezeléséhez, valamint egy kiterjesztett utasításkészletet, amely az adott társprocesszor speciális feladataira lett szabva.
Oké, most talán kezdi látni a körvonalait annak, amihez megérkeztünk. Az Apple M1 valóban az iparág egészét a társprocesszorok által uralt jövő felé fogja tolni. És ezeknek a társprocesszoroknak az elkészítéséhez a RISC-V a rejtvény fontos része lesz.
De miért? Nem lehet, hogy mindenki, aki társprocesszort készít, egyszerűen feltalálja a saját utasításkészletét? Végül is szerintem az Apple ezt tette. Vagy esetleg ARM-et használnak. Fogalmam sincs. Ha valaki tudja, kérem írjon.
Milyen előnyökkel jár a RISC-V társprocesszorokhoz ragaszkodás?
A chip készítés bonyolult és költséges tevékenységgé vált. Eszközök létrehozása a chip ellenőrzéséhez. A tesztprogramok futtatása, a diagnosztika és sok más dolog nagy erőbefektetést igényel.
Ez része annak az értéknek, ami ma az ARM-mel együtt jár. Eszközök széles ökoszisztémájával rendelkezünk, amelyek segítenek ellenőrizni és tesztelni a tervezést.
Nem jó ötlet az egyedi, védett utasításkészletek használata. A RISC-V-vel létezik egy szabvány, amelyhez több vállalat is készíthet eszközöket. Hirtelen egy ökoszisztéma alakul ki, és több vállalat is megoszthatja a terheket.
De miért nem használja az ARM-et, amely már létezik? Hiszen az ARM általános célú CPU-nak készült. Nagy, fix utasításkészlettel rendelkezik. Az ügyfelek nyomására és a RISC-V versenyre az ARM engedett, és 2019-ben megnyitotta a lehetőséget az utasításkészlet bővítésére.
Mégis az a probléma, hogy kezdettől fogva nem erre készült. Az egész ARM eszközlánc azt feltételezi, hogy a teljes nagy ARM utasításkészletet felhasználják. Ez egy Mac vagy iPhone fő CPU-jához jó.
De egy társprocesszornak nincs szüksége erre a nagy utasításkészletre. Olyan eszközök ökoszisztémájára van szükség, amelyek egy minimális fix alap utasításkészlet ötlete köré építenek kiterjesztésekkel.
Az Nvidia RISC-V alapú vezérlőket használ
Miért olyan előny ez? Az Nvidia RISC-V használata némi betekintést nyújt. A nagy GPU-hoz valamilyen általános célú CPU-ra van szükségük, hogy vezérlőként használják őket. Azonban a szilícium mennyisége, amit erre félre tudnak tenni, és az általuk termelt hőmennyiség minimális. Ne feledje, hogy sok minden verseng a helyért.
A RISC-V kicsi és egyszerű utasításkészlete lehetővé teszi a RISC-V magok sokkal kevesebb szilíciumból való megvalósítását, mint az ARM.
Mivel a RISC-V olyan kicsi és egyszerű utasításkészlettel rendelkezik, minden versenytársat legyőz, beleértve az ARM-et is. Az Nvidia úgy találta, hogy a RISC-V-vel kisebb chipeket tudnak készíteni, mint bárki más. A wattfogyasztást is minimálisra csökkentették.
A kiterjesztések mechanizmusával korlátozhatjuk magunkat arra, hogy csak azokat az utasításokat adjuk hozzá, amelyek elengedhetetlenek az elvégzendő munkához. Például a GPU vezérlőjének valószínűleg más bővítményekre van szüksége, mint egy titkosítási társprocesszor vezérlőjének.
RISC-V Machine Learning Accelerator (ET-SOC-1)
Az Esperanto Technologies egy másik vállalat, amely értéket talált a RISC-V-ben. Készítenek egy ET-SOC-1 névre keresztelt SoC-t, amely valamivel nagyobb, mint az M1 SoC. 23,8 milliárd tranzisztorral rendelkezik, szemben az M1-es 16 milliárddal.
Négy általános célú Firestorm mag helyett négy RISC-V magként, ET-Maxion néven. Ezek általános célokra alkalmasak, például Linux operációs rendszer futtatására. De ezen felül több mint 1000 speciális ET-Minion társprocesszorral rendelkezik. Ezek RISC-V alapú társprocesszorok, amelyek megvalósítják a RISC-V vektorbővítést. Mi ennek a jelentősége? Ezek az utasítások különösen alkalmasak nagy vektorok és mátrixok feldolgozására, amelyekről a modern gépi tanulás szól.
Lehet, hogy hitetlenkedve nézi a magok számát. Hogyan lehet az ET-SOC-1-nek annyi magja, mint az M1-nek? Ennek az az oka, hogy a Firestorm mag a tipikus asztali munkaterhelések kezelésére szolgál, amelyeket nem lehet könnyen párhuzamosítani. Ezért sok trükköt kell bevetni, hogy megpróbáljunk párhuzamosan futtatni egy kódot, amelyet nem triviális párhuzamosítani. Ez sok szilíciumot felemészt. Ezzel szemben az ET-Minion magok olyan problémákkal foglalkoznak, amelyeket triviális párhuzamosítani, így ezek a magok nagyon egyszerűek lehetnek, csökkentve a szükséges szilícium mennyiségét.
Az ET-SOC-1 kulcsfontossága az, hogy a magasan specializált társprocesszorok gyártói értéket látnak a RISC-V alapú társprocesszorok építésében. Mind az ET-Maxion, mind az ET-Minion magok licencelhetőek lesznek az Esperanto Technologies-tól. Ez elméletben azt jelenti, hogy az Apple (vagy bárki más) licencelhetne ET-Minion magokat, és rengeteget rakhat belőlük az M1-re, hogy kiváló gépi tanulási teljesítményt érjen el.

Az eszperantó ET-SoC-1 kockarajz. Kép: Art Swift.
Az ARM lesz az új x86
Ironikus módon egy olyan jövőt láthatunk, ahol a Mac-ek és PC-k ARM processzorokkal működnek. De a körülöttük lévő összes egyedi hardvert, az összes társprocesszort a RISC-V fogja uralni. Ahogy a társprocesszorok egyre népszerűbbek, a System-on-a-Chip (SoC) szilícium lapkákban egyre több lesz, amelyen RISC-V fut, mint amin ARM.
Amikor a RISC-V: Rosszul választott az Apple? történetet írtam, valójában nem fogtam fel teljesen, miről is szól a RISC-V. Azt gondoltam, a jövő az ARM-ről vagy a RISC-V-ről szól. De ehelyett valószínűleg ARM és RISC-V lesz.
Az ARM utasítja a RISC-V társprocesszorok hadseregét
Az általános célú ARM processzorok állnak majd a középpontban egy sereg RISC-V-vel működő társprocesszorral, amelyek minden lehetséges feladatot felgyorsítanak a grafikától, titkosítástól, videókódolástól, gépi tanulástól, jelfeldolgozástól a hálózati csomagok feldolgozásáig.
Prof. David Patterson és csapata a Berkeley Egyetemen látta, hogy ez a jövő közeledik, és ezért van a RISC-V olyan jól szabott, hogy megfeleljen ennek az új világnak.
Olyan masszív elterjedést és felhajtást látunk a RISC-V körül mindenféle speciális hardverben és mikrovezérlőben, hogy úgy gondolom, az ARM által manapság uralt területek nagy része RISC-V lesz.
Képzeljünk el olyasmit, mint a Raspberry Pi. Most ARM futtatja. A jövőbeli RISC-V-megoldások azonban számos változatot kínálhatnak, amelyek különböző igényekre vannak szabva. Lehetnének gépi tanulási mikrokontrollerek. Egy másik lehet képfeldolgozás-orientált. A harmadik specializáltan a titkosításra. Alapvetően választhat egy kis mikrovezérlőt, saját ízesítéssel. Lehetséges, hogy Linuxot futtathat rajta, és ugyanazokat a feladatokat végezheti el, csak a teljesítményprofil eltérő lesz.
A speciális gépi tanulási utasításokkal rendelkező RISC-V mikrokontrollerek gyorsabban képezik a neurális hálózatokat, mint a videó kódolási utasításokkal rendelkező RISC-V mikrokontrollerek.
Az Nvidia már bevállalta ezt az utat Jetson Nano-jával, amely alább látható. Ez egy Raspberry Pi méretű mikrokontroller speciális hardverrel a gépi tanuláshoz, így objektumészlelést, beszédfelismerést és egyéb gépi tanulási feladatokat végezhet.

Rasberry Pi 4 Mikrovezérlő, ARM processzorral

Nvidia Jetson Nano fejlesztői kit
RISC-V mint fő CPU?
Sokan kérdezik: Miért nem cserélik le teljesen az ARM-et RISC-V-re? Míg mások azt állítják, hogy ez soha nem működne, mert a RISC-V „csekély és egyszerű” utasításkészlettel rendelkezik, amely nem képes olyan nagy teljesítményt nyújtani, mint az ARM és az x86.
Igen, használhatjuk a RISC-V-t fő processzorként. Nem, a teljesítmény nem akadályoz meg bennünket ebben. Csakúgy, mint az ARM-nél, szükségünk van valakire, aki készít nagy teljesítményű RISC-V chipet. Valójában már megtörténhetett: az új RISC-V CPU rekordot döntő wattonkénti teljesítményt állít fel.
Általános tévhit, hogy az összetett utasítások nagyobb teljesítményt nyújtanak. A RISC munkaállomások ezt megcáfolták a 90-es években, mivel a teljesítmény-benchmarkok során megsemmisítették az x86-os számítógépeket.
Hogyan győzte le az Intel a RISC munkaállomásokat a 90-es években: Vége a játéknak az x86 ISA és az Intel számára?
Valójában a RISC-V számos okos trükköt rejt magában a nagy teljesítmény elérése érdekében: A RISC-V mikroprocesszorok géniusza.
Röviden, semmi oka annak, hogy a fő CPU miért ne lehetne RISC-V processzor, de ez is lendület kérdése. A macOS és a Windows már fut ARM-en. Legalábbis rövid távon kérdésesnek tűnik, hogy akár a Microsoft, akár az Apple újabb hardveres átállásra fordítja-e az erőfeszítéseit.
Oszd meg a gondolataidat
Tudasd velem mire gondolsz. Sok minden történik itt, amit nehéz kitalálni. Látjuk pl. most olyan RISC-V CPU-król van szó, amelyek watt és teljesítmény tekintetében valóban felülmúlják az ARM-et. Ebből arra is gondolhatunk, hogy valóban van esélye, hogy a RISC-V a számítógépek központi CPU-jává váljon.
Bevallom, számomra nem volt nyilvánvaló, hogy a RISC-V miért múlja felül az ARM-et. Saját bevallásuk szerint a RISC-V meglehetősen konzervatív kialakítás. Nem sok olyan utasítást használnak, amelyeket más régebbi kivitelben még nem használtak.
Úgy tűnik azonban, hogy jelentős előnyökkel jár, ha mindent a minimumra hangolunk. Lehetővé teszi kivételesen kicsi és egyszerű implementációk vagy RISC-V CPU-k készítését. Ez pedig lehetővé teszi a wattfogyasztás csökkentését és az órajel frekvenciájának növelését. Vagyis még nem mondták ki az utolsó szót a RISC-V-ről és az ARM-ről.